Recently I played with Open vSwitch and it’s awesome! Open vSwitch is a multilayer virtual switch and it brings a lot of flexibility in the way you can create interfaces and bridges in Linux. It’s also a Linux distribution independent way to configure these things. Switching in software!
To create a bridge, simply run:
ovs-vsctl add-br remibr0
You can also create another bridge on top of it, to handle a VLAN for example:
ovs-vsctl add-br mgmt0 remibr0 101
Even better, create a bond based on LACP:
ovs-vsctl add-bond remibr0 bond0 em49 em50 bond_mode=balance-tcp lacp=active other_config:lacp-time=fast
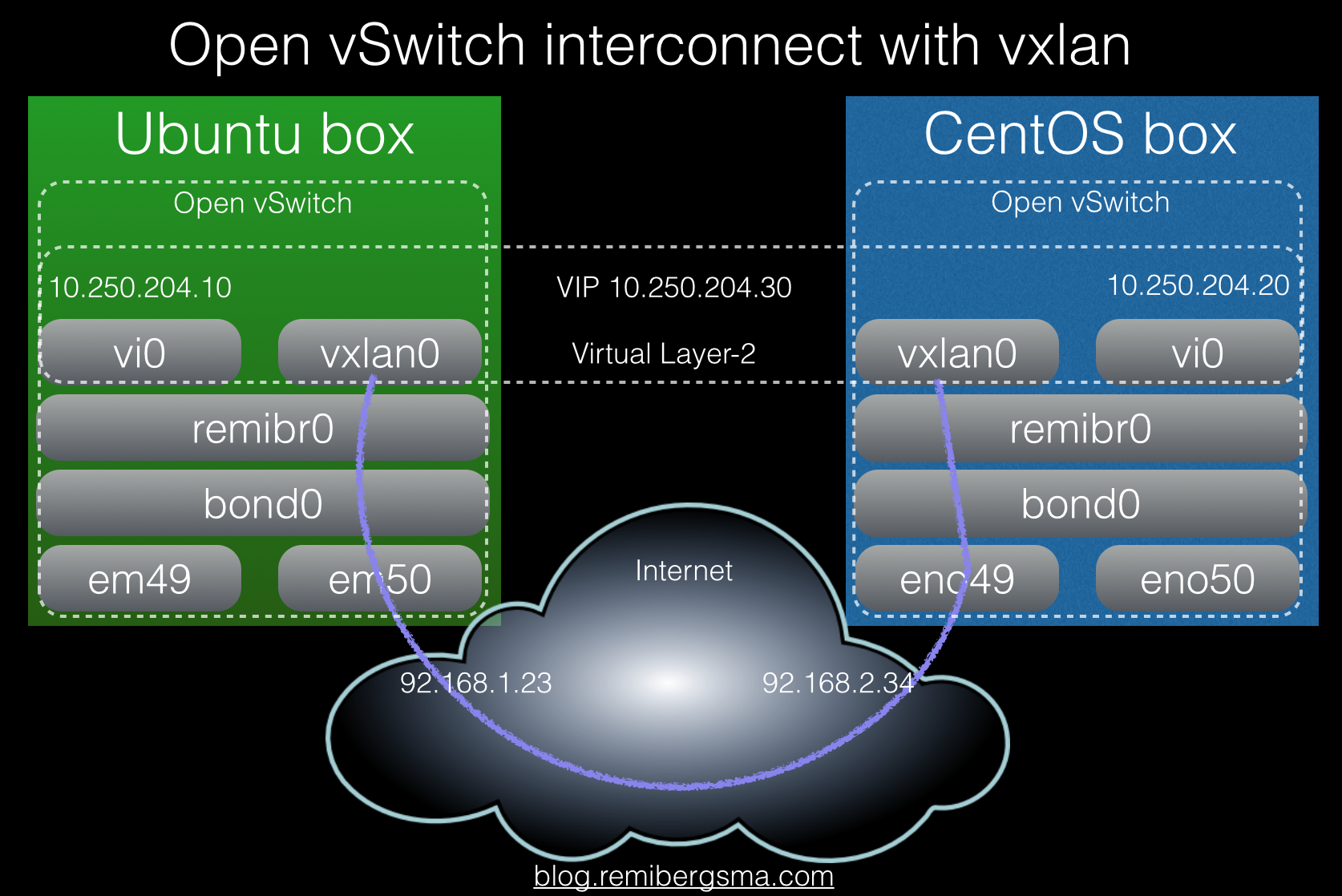
This is all quite nice but still basic. It gets interesting when you realise you can connect two switches like you can put a patch cable between physical switches. To test how cross platform this works, I setup two boxes: a CentOS 7 box and a Ubuntu 15.04 one. This shows it in a picture:
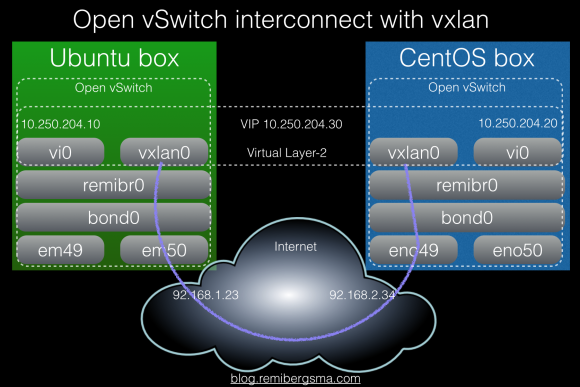
We’ll create a new bridge and add a vxlan interface that connects to the other vswitch. Then create a port on it and assign it an ip address. Installing Open vSwitch should be simple, as it is included in the releases.
Create the configuration and be sure to fill in the right ip addresses.
ovs-vsctl add-br remibr0
ovs-vsctl add-port remibr0 vxlan0 -- set Interface vxlan0 type=vxlan options:remote_ip=92.168.1.23
ovs-vsctl add-port remibr0 vi0 -- set Interface vi0 type=internal
ifconfig vi0 10.250.204.10/24 up
On the second box, bring up 10.25.204.20/24 on vi0.
Your config should look like this:
ovs-vsctl show
f11505d7-199c-4fa9-9f3a-21016ab4fded
Bridge "remibr0"
Port "vxlan0"
Interface "vxlan0"
type: vxlan
options: {remote_ip="92.168.1.23"}
Port "remibr0"
Interface "remibr0"
type: internal
Port "vi0"
Interface "vi0"
type: internal
ovs_version: "2.3.1"
And on the second box:
ovs-vsctl show
Output:
129f100b-1377-46bd-89ba-eaf1f1bc5162
Bridge "remibr0"
Port "vi0"
Interface "vi0"
type: internal
Port "vxlan0"
Interface "vxlan0"
type: vxlan
options: {remote_ip="92.168.2.34"}
Port "remibr0"
Interface "remibr0"
type: internal
ovs_version: "2.3.90"
As you can see, I used different versions on purpose. You can use two boxes that are the same, of course.
By now, a simple ping test should work:
PING 10.250.204.20 (10.250.204.20) 56(84) bytes of data.
64 bytes from 10.250.204.20: icmp_seq=1 ttl=64 time=0.019 ms
64 bytes from 10.250.204.20: icmp_seq=2 ttl=64 time=0.009 ms
^C
--- 10.250.204.20 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.009/0.014/0.019/0.005 ms
And reversed:
PING 10.250.204.10 (10.250.204.10) 56(84) bytes of data.
64 bytes from 10.250.204.10: icmp_seq=1 ttl=64 time=1.47 ms
64 bytes from 10.250.204.10: icmp_seq=2 ttl=64 time=0.202 ms
^C
--- 10.250.204.10 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.202/0.839/1.477/0.638 ms
Create a virtual floating ip address
To make the demo a bit more advanced, let’s setup a virtual ip address on the interfaces that can travel between the switches. We use keepalived for this.
vim /etc/keepalived/keepalived.conf
Add this:
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state MASTER
interface vi0
virtual_router_id 51
priority 200
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.250.204.30/24
}
}
Copy the config to the other box, be sure to have on MASTER and one BACKUP. Also, the priority of the MASTER should be 200 and the BACKUP 100. It’s just a demo, all it does it bring up an ip address.
Start them both and they should discover each other over the vi0 interfaces on the connected vswitches.
Try pinging the virtual ip address:
PING 10.250.204.30 (10.250.204.30) 56(84) bytes of data.
64 bytes from 10.250.204.30: icmp_seq=1 ttl=64 time=0.045 ms
64 bytes from 10.250.204.30: icmp_seq=2 ttl=64 time=0.031 ms
64 bytes from 10.250.204.30: icmp_seq=3 ttl=64 time=0.023 ms
^C
--- 10.250.204.30 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 1998ms
Depending on where the virtual address resides, the latency may be different:
PING 10.250.204.30 (10.250.204.30) 56(84) bytes of data.
64 bytes from 10.250.204.30: icmp_seq=1 ttl=64 time=0.481 ms
64 bytes from 10.250.204.30: icmp_seq=2 ttl=64 time=0.202 ms
64 bytes from 10.250.204.30: icmp_seq=3 ttl=64 time=0.215 ms
64 bytes from 10.250.204.30: icmp_seq=4 ttl=64 time=0.203 ms
^C
--- 10.250.204.30 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 2998ms
rtt min/avg/max/mdev = 0.202/0.275/0.481/0.119 ms
Now start a ping and stop keepalived, then start it again and stop it on the other side. You’ll miss a ping or two when it fails over and then it will recover just fine.
PING 10.250.204.30 (10.250.204.30) 56(84) bytes of data.
64 bytes from 10.250.204.30: icmp_seq=1 ttl=64 time=0.824 ms
64 bytes from 10.250.204.30: icmp_seq=2 ttl=64 time=0.167 ms
64 bytes from 10.250.204.30: icmp_seq=3 ttl=64 time=0.160 ms
64 bytes from 10.250.204.30: icmp_seq=4 ttl=64 time=0.148 ms
64 bytes from 10.250.204.30: icmp_seq=5 ttl=64 time=0.149 ms
From 10.250.204.10: icmp_seq=6 Redirect Host(New nexthop: 10.250.204.30)
From 10.250.204.10 icmp_seq=6 Redirect HostFrom 10.250.204.10: icmp_seq=7 Redirect Host(New nexthop: 10.250.204.30)
From 10.250.204.10 icmp_seq=7 Redirect Host64 bytes from 10.250.204.30: icmp_seq=8 ttl=64 time=0.012 ms
64 bytes from 10.250.204.30: icmp_seq=9 ttl=64 time=0.025 ms
64 bytes from 10.250.204.30: icmp_seq=10 ttl=64 time=0.012 ms
64 bytes from 10.250.204.30: icmp_seq=11 ttl=64 time=0.016 ms
64 bytes from 10.250.204.30: icmp_seq=12 ttl=64 time=0.011 ms
64 bytes from 10.250.204.30: icmp_seq=13 ttl=64 time=0.011 ms
From 10.250.204.10: icmp_seq=14 Redirect Host(New nexthop: 10.250.204.30)
From 10.250.204.10 icmp_seq=14 Redirect HostFrom 10.250.204.10: icmp_seq=15 Redirect Host(New nexthop: 10.250.204.30)
From 10.250.204.10 icmp_seq=15 Redirect Host64 bytes from 10.250.204.30: icmp_seq=16 ttl=64 time=0.323 ms
64 bytes from 10.250.204.30: icmp_seq=17 ttl=64 time=0.162 ms
64 bytes from 10.250.204.30: icmp_seq=18 ttl=64 time=0.145 ms
64 bytes from 10.250.204.30: icmp_seq=19 ttl=64 time=0.179 ms
64 bytes from 10.250.204.30: icmp_seq=20 ttl=64 time=0.147 ms
^C
--- 10.250.204.30 ping statistics ---
20 packets transmitted, 16 received, +4 errors, 20% packet loss, time 19000ms
rtt min/avg/max/mdev = 0.011/0.155/0.824/0.193 ms
Note on the MTU when travelling over the internet
vxlan is encapsulation and this obviously needs space in the packets send over the wire. If you travel over networks that have a default MTU of 1500, it may be wise to lower the MTU of the vi0 interfaces as this will prevent fragmentation. Lowering the MTU is a simple work-around. You could also have a look at GRE tunnels instead.
To alter the MTU:
ip link set dev vi0 mtu 1412
You can make this persistent in Ubuntu’s ‘interfaces’ file and add ‘mtu 1400’. Red Hat alike systems have ‘ifcfg-*’ files for each interface. Add ‘MTU=1400’ to them to alter the MTU.
Conclusion
Although this is a simple demo, the real power comes when you use this to connect two different (virtual or physical) networks in different data centers. You’ll be able to create a Layer-2 network over Layer-3. It’s simple, fast and awesome.