


Watch my keynote about the “The Mission Critical Cloud” at CloudStack Collaboration Conference in Dublin, on October 8th 2015.
The slides can be found in this post.
Watch my keynote about the “The Mission Critical Cloud” at CloudStack Collaboration Conference in Dublin, on October 8th 2015.
The slides can be found in this post.

Here are the slides from my talk about CloudStack automation, at the CloudStack Collaboration Conference in Dublin today.
Here are the slides from my keynote presentation at the CloudStack Collaboration Conference in Dublin today.
Tomorrow I’ll do another presentation and talk about automation cloud operations!
At Schuberg Philis, we manage quite a farm of XenServer clusters. As the number of clusters we operate goes up, so goes the time it takes to manage them all. And, let’s be honest: patching and upgrading isn’t the most exciting work. We needed more automation and I took the challenge 😉
The challenge
Patching itself is not a challenge, as we automated that already using Chef. The challenge comes when maintenance tasks require a hypervisor reboot in order to take effect. In such cases, some magic is needed to keep all VMs running, because we aim for zero down time due to maintenance. This blog describes how I automated rebooting full XenServer clusters while all VMs keep running.
N+1 concept
Our clusters are designed based on N+1, which means that if we have a cluster of 6 XenServer hypervisors, we use ~83% (5/6) of its capacity. In this case, when one hypervisor crashes, we have still room for the VMs on the crashed hypervisor, to start again on one of the remaining hosts.
When executing maintenance on our hypervisors, we also use this concep. In this case, we make one hypervisor empty by live migrating all its VMs to the other hypervisors. Now, without any VMs left on it, we can easily patch or upgrade that hypervisor without impact.
Goal
The goal that I had in mind was that I wanted to be able to run a one-liner to automatically reboot a XenServer cluster. Based on the N+1 principle above, that should be possible. The image below shows the process:
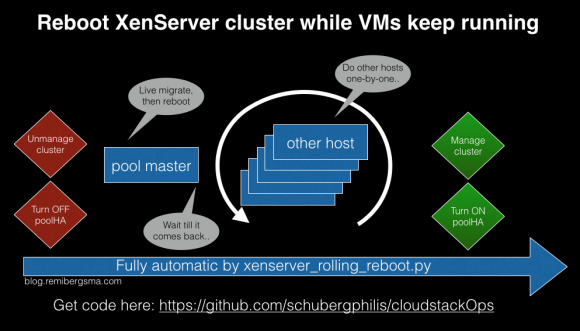
This is what happens:
About CloudStack and XenServer
Since XenServer has the concept of a pool (you could call it a cluster) and one of the hosts is the pool master (it distributes the work to the other cluster members), it is important to know that we need to start with the pool master.
If you want to be sure CloudStack is not touching the cluster while you are performing maintenance, you can put it to an ‘Unmanaged state‘. In the old days we had to do this to prevent CloudStack from electing a new pool master while the previous one was rebooting. As it now relies on XenHA to handle electing a new pool master, I think it’s not needed per se. I just kept it in the scripts to be sure.
 CloudStackOps
CloudStackOps
The script I wrote for this is called ‘xenserver_rolling_reboot.py‘ and is part of the CloudStackOps Toolbox. If you haven’t heard of it before, please check this video of a recent talk I did.
You can get the code from Github.
The one-liner
Now the fun part! All I have to do to reboot a XenServer cluster that is called ‘CLUSTER-1‘ is this:
./xenserver_rolling_reboot.py --clustername CLUSTER-1
To be sure, you need to specify –exec to make it actually do something.
./xenserver_rolling_reboot.py --clustername CLUSTER-1 --exec
Demo time 🙂
I recorded a screencast that demonstrates how it works. Check this video:
As we saw, the script live migrates all VMs off of the pool master, then reboots it. After that, it does the same with all the other hosts. One-by-one. Until they are all rebooted. All VMs stay online during the maintenance.
About live migrations
You would think that it’d be easiest to have CloudStack do the live migrations, and I thought that too. The problem is, that CloudStack live migrates the VMs to a random hypervisor in the same cluster. It depends a bit on the deployment planner but I found little difference in this case. Why is that a problem? Well, you could end up ‘pushing VMs forward’ all the time. I want to live migrate a VM as less times as possible. This makes the whole process a lot faster. Let’s have a look on how the live migrations should work in my opinion:





Conclusion: VMs on the pool master will be live migrated twice. All others only once. Optionally we could rebalance the cluster, causing more live migrations. For now, I kept it to the minimum as I’m OK with some hosts being almost empty.
In order to control the live migrations shown in the images above, I decided to talk to Xapi directly instead of to CloudStack.
Speeding up live-migrations
Unfortunately the whole process was quite slow when I first tested it. The first idea was to use ‘xe host-evacuate‘ but this script can only do one live migration at a time. I asked some XenServer folks about it. Conclusion is that it cannot be done at this time.
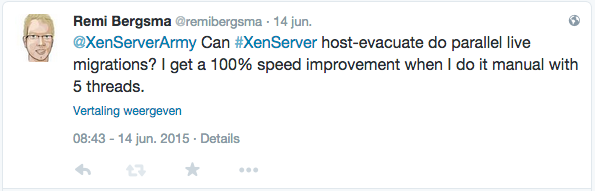
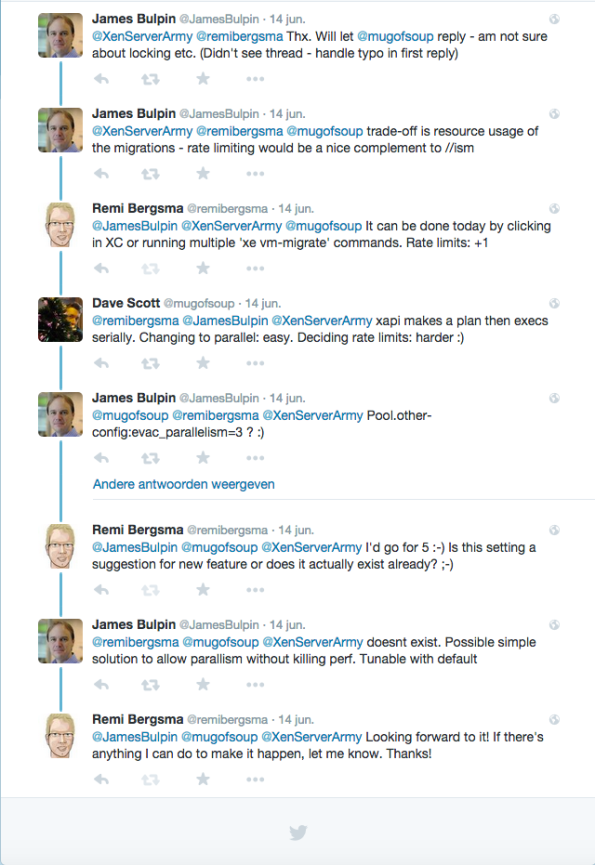
Well, that means I’d to come up with something of my own to speed up the live migrations. To prove it would be possible to migrate faster, we used XenCenter and clicked around. We could easily do 5-10 threads and it was a lot faster. But who wants to click these days? Not me.
After some searches on Google I came up with a very simple solution: use the -P flag of xargs. I wrote a small script that looks up the VMs running on the hypervisor you run the script and it will then calculate a migration plan according to what we discussed above. Then, I’d have a list of ‘xe vm-migrate‘ commands that I run in parallel using xargs. Very simple, very effective.
By using 5 threads, I got twice the speed so that saved a lot of waiting time. I also tried more threads, but it didn’t go any faster. The ‘xenserver_rolling_reboot.py‘ script has a –threads flag, so feel free to play with it. It defaults to 5 threads.
Verified on Production
My team uses this script to do automated patching and rebooting. For the patching itself we use Chef, but that’s the easy part. Rebooting the clusters is what takes time. Now that it is automated, we only have to keep an eye on it. We used it in production to reboot hundreds of XenServer hypervisors without issues.
Conclusion
Automation is key in today’s cloudy environments. This blog shows how I automated the regular maintenance of our XenServer farm. Patching and rebooting is now easy!
 Today I hosted a CloudStack hands-on workshop at DevOpsDays Amsterdam, together with my colleague Fred Neubauer. It was really awesome to see all attendees building their own CloudStack cloud. And succeeding!
Today I hosted a CloudStack hands-on workshop at DevOpsDays Amsterdam, together with my colleague Fred Neubauer. It was really awesome to see all attendees building their own CloudStack cloud. And succeeding!
Here are the slides and instructions: We proposed the workshop to the CloudStack Collaboration Conference Europe, in Dublin next October so we might do it again!

Fred in action!

That’s me in action!

| Shashi on Setting locales correctly on M… | |
| Sayling Low on Alt-key in OSX-Terminal | |
| Roger on Setting locales correctly on M… | |
| belwardblog on HOWTO discover the ip address… | |
| Guilherme Caeiro Dia… on Setting locales correctly on M… | |
| Terminal Show Multip… on Setting locales correctly on M… | |
| bodhix on RRDtool: moving data between 3… | |
| vasu on One-liner: restore compressed… | |
| Angel on HOWTO quickly add a route in M… | |
| Kar.ma on HOWTO connect to hosts on a re… | |
| Home | MacarioJames.… on Sed inline editing different o… | |
| Mac i problemy z loc… on Setting locales correctly on M… | |
| NearlyNormal on HOWTO enable color for PHP and… | |
| Yong on Connecting two Open vSwitches… | |
| Aysad Kozanoglu on Creating a multi hop SSH tunne… |
