


 XenServer and Apache CloudStack work nicely together and form an easy-to-go couple for many companies. However, not many people know that recent releases changed the cooperation between the two drastically.
XenServer and Apache CloudStack work nicely together and form an easy-to-go couple for many companies. However, not many people know that recent releases changed the cooperation between the two drastically.
I’m not only talking about the shiny new Apache CloudStack 4.5 release, but the change was back ported to recent releases of 4.3.x and 4.4.x as well. This means that if you run XenServer and CloudStack, you need the review the information below carefully.
 I can understand why almost nobody knows, because this was not well discussed and did not end up in the release notes nor documentation either. I talked to many people about this at meetups and thought it’d be useful to write some of it in a blog. I tested it on both versions 6.2 and 6.5.
I can understand why almost nobody knows, because this was not well discussed and did not end up in the release notes nor documentation either. I talked to many people about this at meetups and thought it’d be useful to write some of it in a blog. I tested it on both versions 6.2 and 6.5.
What did change?
XenServer works with the concept of a pool-master that coordinates a lot of stuff in the cluster. CloudStack sends its instructions to the pool-master. What did change? CloudStack used to elect a new XenServer pool-master in the event of a failing pool-master. In the new behaviour CloudStack does nothing and relies on the XenServer poolHA feature to be enabled. XenServer itself now elects a new pool-master.
Why is this a problem?
First of all, if you don’t know and upgrade CloudStack, you will not recover automatically anymore from a pool-master failure. This will most likely cause you to have some stress while you work to getting a failed pool-master back up and running. It doesn’t recover automatically anymore, because CloudStack now relies on XenServer to handle this event, but by default this feature is not enabled. No pool-master means no changes are being made (no VMs start, etc).
Why was this changed?
If you ask me, this is a tricky one. The reason for doing it, was sent to the cloudstack-dev list. The mail points to issues CLOUDSTACK-6177 and CLOUDSTACK-5923 but there’s only a vague description there:
“When XS master is down, CS uses pool-emergency-transition-to-master and pool-recover-slaves API to choose a new master, this API is not safe, and should be only used in emergent situation, this API may cause XS use a little bit old (5 minutes old) version of XS DB, some of object may be missing in the old XS DB, which may cause weird behaviour, you may not be able to start VM.”
In other words, there is a small corner-case in which something not specified can go wrong that might prevent starting VMs. Well, if you upgrade CloudStack and do not turn ON the poolHA feature, guess what? You have a 100% change that no VM will start on the whole cluster. Doesn’t make sense to me. At all.
Another thing that bugs me is that there were no replies on the dev-list and that it was silently merged without proper discussion and documentation. I sent an e-mail about it to the cloudstack-dev list, but not too many people seem to care. On the other hand, I do get some questions about it from time to time.
How did we find out?
We had an outage and needed to recover manually, after which we started looking for the Root Cause of this. If you look at the code and the commit messages, you find this changed behaviour that relies on ‘XS HA’ aka XenServer poolHA. This is the commit; it clearly removes the PoolEmergencyTransitionToMaster function that used to elect a new pool-master.
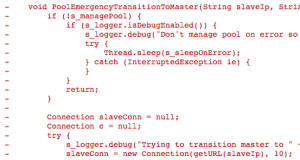
A tricky change
Turning on XenServer poolHA seems easy, but there are pitfalls that can have drastic consequences. Let’s start with the basics. To turn it on, use the ‘xe pool-ha-enable‘ command. You need a Storage Repository that is shared to write heartbeats to. In our case, we already used NFS, so we reused that. If you have no shared SR, be sure to create one.
The XenServer documentation (PDF) says:
“Verify that you have a compatible Storage Repository (SR) attached to your pool. iSCSI, NFS or Fibre Channel are compatible SR types” … “Enable HA on the pool: xe pool-ha-enable heartbeat-sr-uuids=“
So I came up with this:
NFSUUID=$(xe sr-list type=nfs params=uuid --minimal) xe pool-ha-enable heartbeat-sr-uuids=$NFSUUID
The biggest pitfall is that you need to specify the timeout, or else it will use a 30 second default. You’re right, the Citrix manual (linked above) does not tell you this. This caused another outage, this time we lost a whole cluster. Trust me, it was no fun. Fortunately we had application redundancy over multiple clusters. Anyway, my advise: always specify the timeout.
A 30 second timeout means that when your storage or network is unavailable for 30 seconds, all hosts in the cluster will be fenced and reboot. No VM will keep running on that cluster. We use 180 seconds because that is more or less what the ring buffers can hold in our case. Enable HA like this:
NFSUUID=$(xe sr-list type=nfs params=uuid --minimal) xe pool-ha-enable heartbeat-sr-uuids=$NFSUUID ha-config:timeout=180
If you did enable it already, first disable it:
xe pool-ha-disable
To check if HA is enabled, run:
xe pool-list params=all | grep -E "ha-enabled|ha-config"
Output looks like this:
ha-enabled ( RO): true ha-configuration ( RO): timeout: 180
To see all HA properties:
xe pool-list params=all | grep ha-
ha-enabled ( RO): true ha-configuration ( RO): timeout: 180 ha-statefiles ( RO): e57b08d0-aada-4159-c83d-3adea565d22e ha-host-failures-to-tolerate ( RW): 1 ha-plan-exists-for ( RO): 1 ha-allow-overcommit ( RW): true ha-overcommitted ( RO): false
The first three show HA being on, a timeout of 180 seconds and the heartbeats will be written to the storage repository (SR) with uuid e57b08d0-aada-4159-c83d-3adea565d22e.
The setting ‘ha-host-failures-to-tolerate‘ is automatically calculated by XenServer. In our case, it is not important as we do not protect any VMs, we just use the poolHA feature. You can leave this default.
I asked XenServer community manager Tim Mackey about overcommitting when I met him at the CloudStack Day in Austin, TX. He said:
“Setting ha-allow-overcommit to true indicates that XenServer should calculate its HA plan using optimistic placement. Since the point of enabling HA for CloudStack is to handle host failures, but that CloudStack handles all VM level HA, no VMs will actually be protected by XenServer HA. The net result is the value for ha-allow-overcommit shouldn’t matter for CloudStack.”
You need at least three nodes!
Your XenServer pool needs to be at least three XenServers or else the HA feature will not work as expected. Why? Because the poolHA tries to detect isolation. If it cannot see any other host, it assumes it is isolated and self-fences. So, if you have two XenServers and one crashes, the other one becomes isolated and will self-fence. Both are now down, and the bad news is: they will keep fencing because they never are up at the same time. So, they keep thinking they have become isolated from the pool. Nice for a lab, but don’t do this in production.
About Self-Fencing
To prevent corruption, XenServer poolHA fill fence itself if it cannot reach the Storage Repository any more where it is supposed to write its heartbeat. You may find messages like this in the logs:

Warning: Do not protect the VMs
XenServer should only take care of the pool-master failover and the fencing not about restarting VMs as this is CloudStack’s job. The documentation of XenServer instructs you to do it, but just don’t if you use CloudStack. Otherwise both CloudStack and XenServer will try to recover VMs and it will become messy eventually leading to corrupted VMs.
To check HA on VMs is off, run this command:
xe vm-param-get uuid=<UUID> param-name=ha-restart-priority
It should return an empty result. If it does not, make sure to use ‘xe vm-param-set‘ to set it empty.
Warning: Licensing considerations
Before XenServer 6.2, HA was a paid feature. Users of 6.0.2 or 6.1 need a license for this to work. The bad news: if you use a modern CloudStack version, you will need to manually elect a new pool-master.
Warning: PoolHA blocks certain operations
Many operations related to XenServer and CloudStack have changed because they are not allowed when poolHA is enabled.
For example, adding a new XenServer to CloudStack has to be done in a different way as well. If you just add it, you’ll get a message like this in the UI:
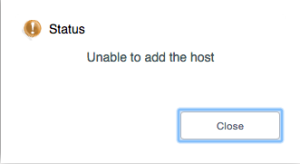
The API does the same:
Error 530: Unable to add the host
Looking at the logs of the management server shows why:
2015-05-23 08:59:03,064 WARN [c.c.h.x.d.XcpServerDiscoverer] (180595423@qtp-818975168-33:ctx-7c741014 ctx-79b8e039) Please join the host 192.168.22.13 to XS pool f4d78d74-1985-d8d7-f1c4-f7b2b5c213b6 through XC/XS before adding it through CS UI
Ah, you need to add it to the XenServer pool first. In other words, when building a new cluster: first you need to make a complete XenServer pool, then add one of them to CloudStack that will discover the others and add them in one go.
When you add an extra XenServer to an existing cluster, be sure to add it to XenServer first and then to CloudStack. Start with disabling poolHA, do your thing and enable poolHA again. if you add more than one new XenServer, adding one to CloudStack will discover them all.
Another example. You can no longer remove the pool-master from CloudStack. You first need to go to the XenServer and designate a new pool-master. That also sounds simple, but it is not allowed when poolHA is enabled. So, you have to:
- disable poolHA
- elect a new pool-master
- remove the XenServer from the pool
- remove the host from CloudStack
- and finally turn on polHA again
Poehee. Same goes for patching, as you change the pool-master as well.
In short: Enabling poolHA brings challenges when automating these operations, as we now need to talk both to CloudStack and XenServer.
Known issue: CloudStack reports Alert state
When one of the XenServer nodes crashes for some reason, be it hardware or else, it sometimes is put into “maintenance mode”. Not in CloudStack, but in the pool itself. CloudStack will report an Alert state and refuse to work with it. You need to manually enable the host again using the ‘xe host-enable‘ command. CloudStack will then automatically enable it again and start using it.
How to go from here?
To be honest I don’t like the “two captain” approach. In my opinion CloudStack is the orchestrator and needs to be in control. Any hypervisor should be dumb and do what the orchestrator (in this case CloudStack) tells it to do. Period. Like how KVM works, I love the simplicity.
I’m investigating if we can get the best of both worlds by detecting whether HA is turned ON (one-liner shown above) and implement a behaviour based on that. If HA is turned OM, do what 4.4+ does today. If it’s turned OFF, do the old behaviour. This essentially makes it possible to choose between the options and I’m quite sure I’ll disable HA again. It is also backwards compatible for those relying on this feature now.
Another thing to improve is the documentation. As a start, I‘ve sent a first pull-request to update it.
Conclusion
If you run XenServer and CloudStack, you may want to enable poolHA on XenServer or else you will have to manually elect a new pool-master in the event of a crash. Be sure to configure it properly and remember that poolHA when enabled brings in extra steps to certain operations. I hope this blogs helps people achieving nice uptimes and easy maintenance.
Update (June 1st):
Things started rolling and Citrix updated their XenServer documentation to include the HA timeout settings. Nice!



Thank you oh my good 🙂