The Raspberry Pi is a $35 credit-card sized computer, with an ARM-based CPU. It uses very little power (only 3 Watt), so it’s ideal for a server that’s always-on. I was thinking what’d be a nice task for my Raspberry Pi and came up with an OpenVPN server. This enables me to connect to my home from anywhere, for example to access some files or to access the internet from there.
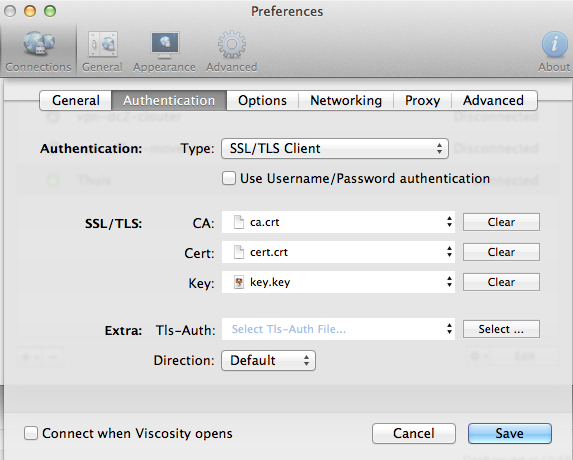
Before we start, Let’s have a look what’s on board the Raspberry Pi so you’ve an idea what we talk about:
Here’s mine in action:

Now, let’s see how we can turn it into a OpenVPN server. Actually this is very easy due to the fact that the Raspberry Pi is running (a modified) Debian Weezy called Raspbian. Since it’s Debian, you can use apt-get to install software:
apt-get install openvpn
After the install finishes, you need to generate keys for the server and the client(s). OpenVPN ships with the ‘easy-rsa’-tool. It’s easiest to copy the example folder and work from there.
cp -R /usr/share/doc/openvpn/examples/easy-rsa /etc/openvpn
cd /etc/openvpn/easy-rsa/2.0
The ‘easy-rsa’-tool has a file called ‘vars’ that you can edit to set some defaults. That will save you time later on but it’s not required to do so.
Load the vars like this (note the two dots):
. ./vars
Then we need to generate keys:
./clean-all
./build-ca
./build-key-server server
./build-key client-name
./build-dh
The first line makes sure we start from scratch. The second generates a key for the Certificate Authority. The key for the server itself is generated on the third line. Repeat the forth line for each client that needs to connect. Finally, we need the Diffie Hellman key as well, which is generated on the fifth line. Make sure you use a 2048 bit key, as suggested in the comments.
We need to copy the keys to the OpenVPN folder.
cd /etc/openvpn/easy-rsa/2.0/keys
cp ca.crt ca.key dh2048.pem server.crt server.key /etc/openvpn
Last step is to configure the server. You can copy the example config and make sure it points to the certs you just created.
cp /usr/share/doc/openvpn/examples/sample-config-files/server.conf.gz /etc/openvpn
gunzip /etc/openvpn/server.conf.gz
vim /etc/openvpn/server.conf
When you’re done, start OpenVPN like this:
/etc/init.d/openvpn start
Response looks like:
[ ok ] Starting virtual private network daemon: server.
Verify it by running:
ifconfig tun0
You’ll see:
tun0 Link encap:UNSPEC HWaddr 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00
inet addr:10.8.0.1 P-t-P:10.8.0.2 Mask:255.255.255.255
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1500 Metric:1
RX packets:49 errors:0 dropped:0 overruns:0 frame:0
TX packets:16 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:100
RX bytes:3772 (3.6 KiB) TX bytes:1212 (1.1 KiB)
Now you should be able to connect to the OpenVPN server with a client. I’m using Viscosity on Mac OSX, but there’re many clients available on almost any platform (Windows, Mac OSX, Linux). You need the client.crt, client.key and ca.crt files plus the ip-address of your Raspberry Pi.
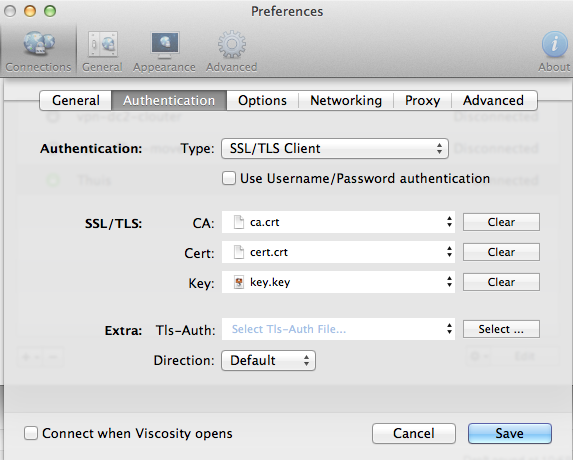
Connecting should now work without trouble. Have a look at ‘/var/log/syslog’ to access the logfiles. You’d be able to see which client connects:
Jan 5 22:07:56 raspberrypi ovpn-server[14459]: 1.2.3.4:64805 [client-name] Peer Connection Initiated with [AF_INET]1.2.3.4:64805
Now that all is working, time for a last tip: when you want to access the network behind the Raspberry Pi through your OpenVPN connection, configure OpenVPN to push the right route to the clients. Edit the OpenVPN server config, and add a parameter like this:
push "route 10.1.7.0 255.255.255.0"
Be sure to enter the network- and netmask address that match your network setup. The route is automatically added on connect, and removed on disconnect.
Finally, enable routing on the Rasperry Pi:
echo 1 > /proc/sys/net/ipv4/conf/all/forwarding
Have fun with it, you can do a lot of great things with this little machine!
Update: Also see these follow-up posts that contain more detailed info on some interesting use cases and help you set it up:
HOWTO connect to hosts on a remote network using OpenVPN and some routing
Secure browsing via untrusted wifi networks using OpenVPN and the Raspberry Pi